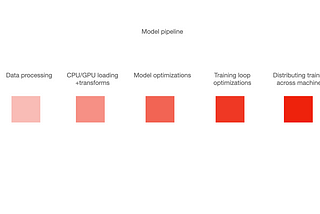
William FalconinTowards Data SciencePyTorch Lightning vs DeepSpeed vs FSDP vs FFCV vs …Learn how to mix the latest techniques for training models at scale using PyTorch Lightning.Mar 17, 2022Mar 17, 2022
William FalconinTowards Data ScienceGPUs Are Fast! Datasets Are Your BottleneckMay 19, 2021May 19, 2021
William FalconinTowards Data ScienceTrivially Scale PyTorch on AWSRun PyTorch workloads on AWS with zero code changesMay 7, 2021May 7, 2021
William FalconinTowards Data ScienceSetting A Strong Deep Learning Baseline In Minutes With PyTorchIterate your way from baseline to custom models to ship products faster or to publish your research faster.Feb 13, 2021Feb 13, 2021
William FalconinTowards Data ScienceSharded: A New Technique To Double The Size Of PyTorch ModelsSharded is a new technique that helps you save over 60% memory and train models twice as largeDec 12, 20202Dec 12, 20202
William FalconinTowards Data ScienceVariational Autoencoder Demystified With PyTorch Implementation.This tutorial implements a variational autoencoder for non-black and white images using PyTorch.Dec 5, 202012Dec 5, 202012
William FalconinTowards Data ScienceOpensource: The magic power of AI research.Opensource is the key to advancing AI. Peek into this from the insider’s perspectiveNov 21, 20201Nov 21, 20201
William FalconinTowards Data SciencePeering Inside The Blackbox — How To Trick A Neural NetworkIn this tutorial, I’ll show you how to use gradient ascent to change the input as to classify it as whatever you would like.Sep 13, 20201Sep 13, 20201
William FalconinTowards Data ScienceA Framework For Contrastive Self-Supervised Learning And Designing A New ApproachWe formulate a framework for characterizing contrastive self-supervised learning approaches and look at AMDIM, CPC, BYOL, SimCLR, and Swav.Sep 2, 20206Sep 2, 20206
William FalconinPyTorchPyTorch Multi-GPU Metrics and more in PyTorch Lightning 0.8.1Today we released 0.8.1 which is a major milestone for PyTorch Lightning. This release includes a metrics package, and more!Jun 20, 20202Jun 20, 20202